eBPF 到底是什麼?一套給開發者的思考模型
把術語拿掉,直接講清楚 eBPF:它到底是什麼、為什麼非得發明它不可、30 秒搞懂它怎麼運作,以及什麼時候該用它。從 tcpdump 一路講到今天,順著它自己的歷史說故事。
TL;DR: eBPF 讓你把又小又被沙箱隔離的程式,直接跑在 Linux kernel 裡面——用來觀察或改變系統正在做的事——而且不用改 kernel、也不用動你的應用程式。如果你跑過
tcpdump,那你其實早就用過 BPF。
問題:kernel 改不動,而要它長出新能力,往往得等上好幾年
Liz Rice 有一張很有名的漫畫,把以前那種痛點講得入木三分:
- 應用程式開發者想要 kernel 提供某個新能力。
- kernel 維護者說:「沒問題——給我一年,讓我去說服整個社群。」
- 一年後它進了 upstream。再過個幾年,你用的發行版才終於把它包進來。
- 等到那時候……你的需求早就變了。
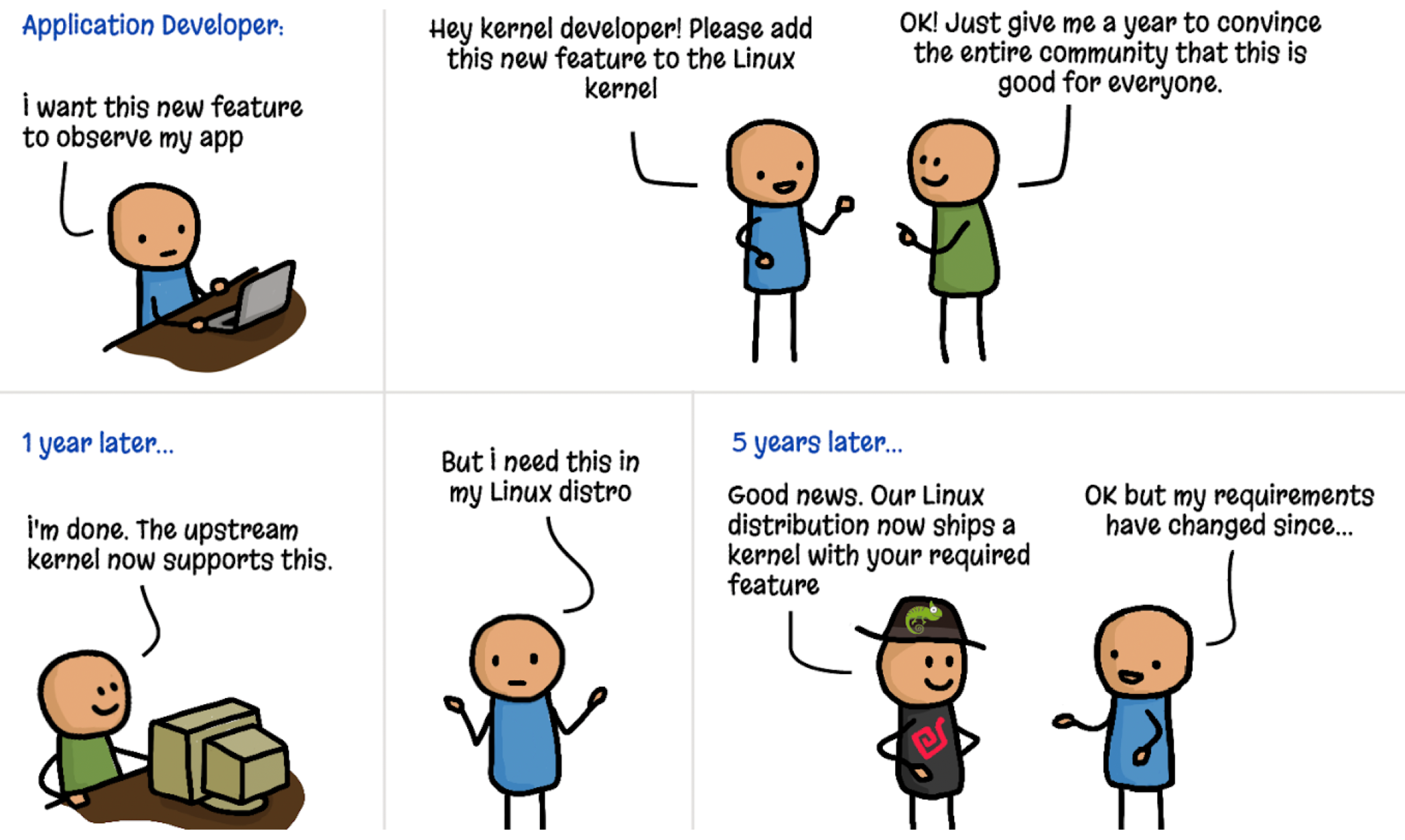 Source: Learning eBPF — Liz Rice
Source: Learning eBPF — Liz Rice
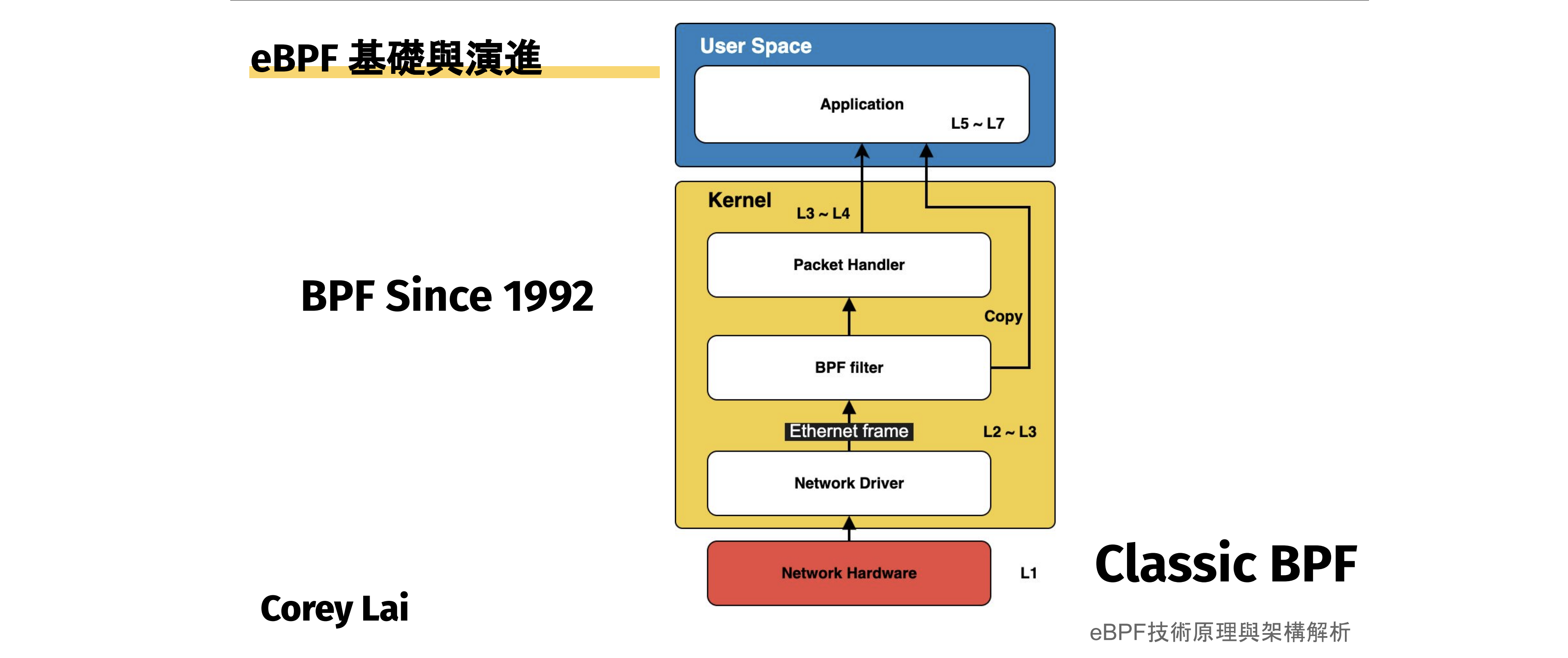
kernel 幾乎看得到系統裡的每一件事:每一次 syscall、每一個封包、每一個檔案操作。而且它是開源的,原始碼完全公開,你想讀多細都行——所以難處從來不是「看不見裡面」,而是「改不動它」:你很難讓一顆正在線上服務的 kernel,安全地長出你當下需要的那個能力。過去要做到這件事,只有兩條都不太好走的路。一是改 kernel 原始碼、重新編譯、重開機——慢、風險高,還得說服上游願意收你的 patch;二是在 user space 外掛一支 agent,靠輪詢 /proc、/sys 從外面旁敲側擊——裝得上,卻拿不到 kernel 內部第一手的事件。eBPF 是第三條路。
你會學到
- eBPF 到底是什麼,用一句話講完
- 它為什麼存在——順著它自己的歷史說(
tcpdump→ 今天) - 30秒看懂它怎麼運作,以及什麼時候該用它(什麼時候不該)
一句話的心智模型
eBPF 是一個跑在 Linux kernel 裡、安全又被沙箱隔離的虛擬機,它會因應事件去執行你寫的小程式——一個封包進來、一個 syscall 被觸發、一個函式被呼叫——讓你能觀察或控制系統,而完全不用改 kernel 原始碼或你的應用程式。
它是一套能在執行期安全載入的 kernel 擴充機制。你掛上去的每一支小程式,都是綁在某個事件上的 hook;但它跟瀏覽器裡那種「想寫什麼就寫什麼」的腳本剛好相反——每一支 eBPF 程式在被放行之前,都得先通過 kernel 內建 verifier 的靜態檢查,能用的指令、迴圈次數、能碰的記憶體都被嚴格限制住。這層限制不是綁手綁腳,而是它能放心跑在線上 kernel 裡的前提。
它為什麼存在:從 Classic BPF 到 eBPF
1992 — Classic BPF(你早就用過了)。 BPF 一開始是當封包過濾器誕生的。每次你跑:
1
tcpdump -i eth0 tcp port 80
……檯面下其實發生了這些事:
tcpdump把你的過濾條件(tcp port 80)交給 libpcap- libpcap 把它編譯成 Classic BPF bytecode
- 一個 syscall 把這段 bytecode 推進 kernel 裡
- kernel 在網路層執行它,只把符合條件的封包往上交給你
這就是整個概念,1992 年就已經成形:把一支小程式推進 kernel 裡,讓工作在那裡做完,而不是在你的應用程式裡。(你甚至可以用 tcpdump -ddd 看到編譯出來的 bytecode。)
約 2014 — extended BPF(eBPF)。 同一套概念被一般化,遠遠超出了封包的範圍。現在你幾乎可以把小程式掛到 kernel 裡的任何東西——syscall、函式的進入/離開、排程器、記憶體、整個網路堆疊。Brendan Gregg 那張很有名的 BPF performance tools 圖,就展示了它擴散得有多廣:幾乎 kernel 的每一層,都有一個由 eBPF 驅動的工具。
它怎麼運作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Your C code
│ clang / LLVM
▼
eBPF bytecode (.o, an ELF object)
│ bpf() syscall (via libbpf / bpftool / BCC)
▼
┌──────────────────── Kernel ────────────────────┐
│ 1. Verifier → checks it's safe │
│ (no crashes, no infinite loops) │
│ 2. (JIT) → runs in the BPF virtual machine │
│ 3. Attached to a hook: │
│ tracepoint / kprobe / XDP / tc / ... │
└───────────────────┬─────────────────────────────┘
│ maps / ring buffer
▼
Your user-space app reads the data
有兩件事讓這套機制既安全又實用:
- verifier(驗證器) 會在程式跑起來之前,就把任何可能讓 kernel 當機或卡死的程式擋下來。這也是 eBPF 能放心跑在 production 的根本原因。
- maps 與 ring buffer 則是 kernel 端的程式和你的 user-space 程式互通資料的管道。
你可以掛載的位置——也就是你在真實程式碼裡會看到的 SEC(...):
| Hook | 層級 | 用途 |
|---|---|---|
xdp | 網卡驅動 | 最快的封包處理、擋 DDoS、負載平衡 |
tc | traffic control | 封包整形(shaping)、分類 |
tracepoint/... | kernel tracepoint | syscall、檔案操作、排程事件 |
fentry/fexit | kernel 函式(CO-RE) | 低負擔的函式追蹤 |
usdt | user space | 追蹤應用程式內部(例如 SQL 查詢耗時) |
大家實際上怎麼寫它(挑一個入門點)
你幾乎不會直接碰原始的 bytecode進行開發。
常見的工具鏈有:
| 工具鏈 | 語言 | 最適合 |
|---|---|---|
| C + libbpf | C | 正式環境;CO-RE(vmlinux.h + BTF)→ 可攜、一次編譯到處跑 |
| BCC | Python + C | 快速做原型;相依比較重 |
| bpftrace | 一套小型 DSL(類似 awk) | 一行指令的 one-liner 與臨時追蹤 |
| cilium/ebpf | Go | 把 eBPF 嵌進 Go 服務裡 |
| aya | Rust | kernel 端與 user space 都用 Rust,型別安全 |
剛開始入門?用 bpftrace 去探索,等你準備好要做點正式的東西時,再換 C + libbpf。
什麼時候該用 eBPF(什麼時候不該)
eBPF 在 observability、網路、安全性與效能分析這些場景特別亮眼——只要你需要 kernel 等級的可視性或控制權,又想把負擔壓到最低,它就派得上用場。底下是它跟常見做法擺在一起的比較:
| 做法 | 它怎麼看你的系統 | 取捨 |
|---|---|---|
| Agent 型(例如 Prometheus exporter) | 輪詢 /proc、/sys | 簡單,但有持續的負擔、而且看得不夠深 |
| 函式庫型(例如 OpenTelemetry SDK) | 你自己在程式碼裡埋點 | 資訊豐富,但你得改每一支應用程式 |
| kernel 型(eBPF) | 直接掛在 kernel 上 | 又深又低負擔、不用改應用程式——但只限 Linux,學習曲線較陡 |
不要用 eBPF 的時機:已經有現成的簡單工具能搞定這件事;你跑在很舊的 kernel 上(很多功能需要 5.x 以上,ring buffer 需要 5.8 以上);或者你根本不在 Linux 上(它是 Linux kernel 的技術——在 Mac 上你得把它跑在 Linux VM 裡)。
自己動手試(不用編譯器)
要親眼看到 eBPF 運作,最快的方法就是即時追蹤你機器啟動的每一支程式。任何一台 Linux 機器,裝個 bpftrace 就行:
1
2
3
4
sudo apt install -y bpftrace
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_execve {
printf("%-6d %-16s %s\n", pid, comm, str(args->filename));
}'
另開一個終端機,隨便跑點東西(ls、date),它馬上就會冒出來:
1
2
3310 bash /usr/bin/ls
3310 bash /usr/bin/date
那就是一支貨真價實的 eBPF 程式:掛在 kernel 的某個 tracepoint 上、通過了 verifier 的檢查,然後持續把事件串流到 user space——沒改 kernel,也沒動應用程式。
想看成熟版(C + libbpf、CO-RE、ring buffer,還有一套正規的 make 建置)嗎?完整、可實際執行的範例——hello-ebpf——就放在文末連結的 repo 裡。
用 Mac?eBPF 只限 Linux——把上面那段程式跑在一台快速開好的 Ubuntu VM 裡(Multipass/Lima)。repo 的 README 有一行指令就能搞定的安裝方式。
重點整理
- eBPF=跑在 kernel 裡、事件驅動的安全程式——不用改 kernel、也不用動你的應用程式,就能觀察或控制系統。
- 它把 kernel 從一個你只能讀、卻很難改的執行環境,變成可以在執行期安全擴充的平台——而 verifier 正是這件事能放心上 production 的關鍵。
- 它很強大,但不是沒有代價:要用對問題(需要深層可視性、低負擔、跑在 Linux),也要在對的時機(夠新的 kernel)。能用更簡單的工具解決的地方,就別硬上 eBPF。
延伸資源
- 我的動手做範例:github.com/hyperredstart/hello-ebpf
- Learning eBPF — Liz Rice(那張漫畫就出自這本書)
- BPF Performance Tools — Brendan Gregg
- ebpf.io
🌐 English version (dev.to): What is eBPF, Really? — A Builder’s Mental Model
剛接觸 eBPF?留言告訴我哪一個觀念你還覺得霧霧的,我來幫你講清楚。