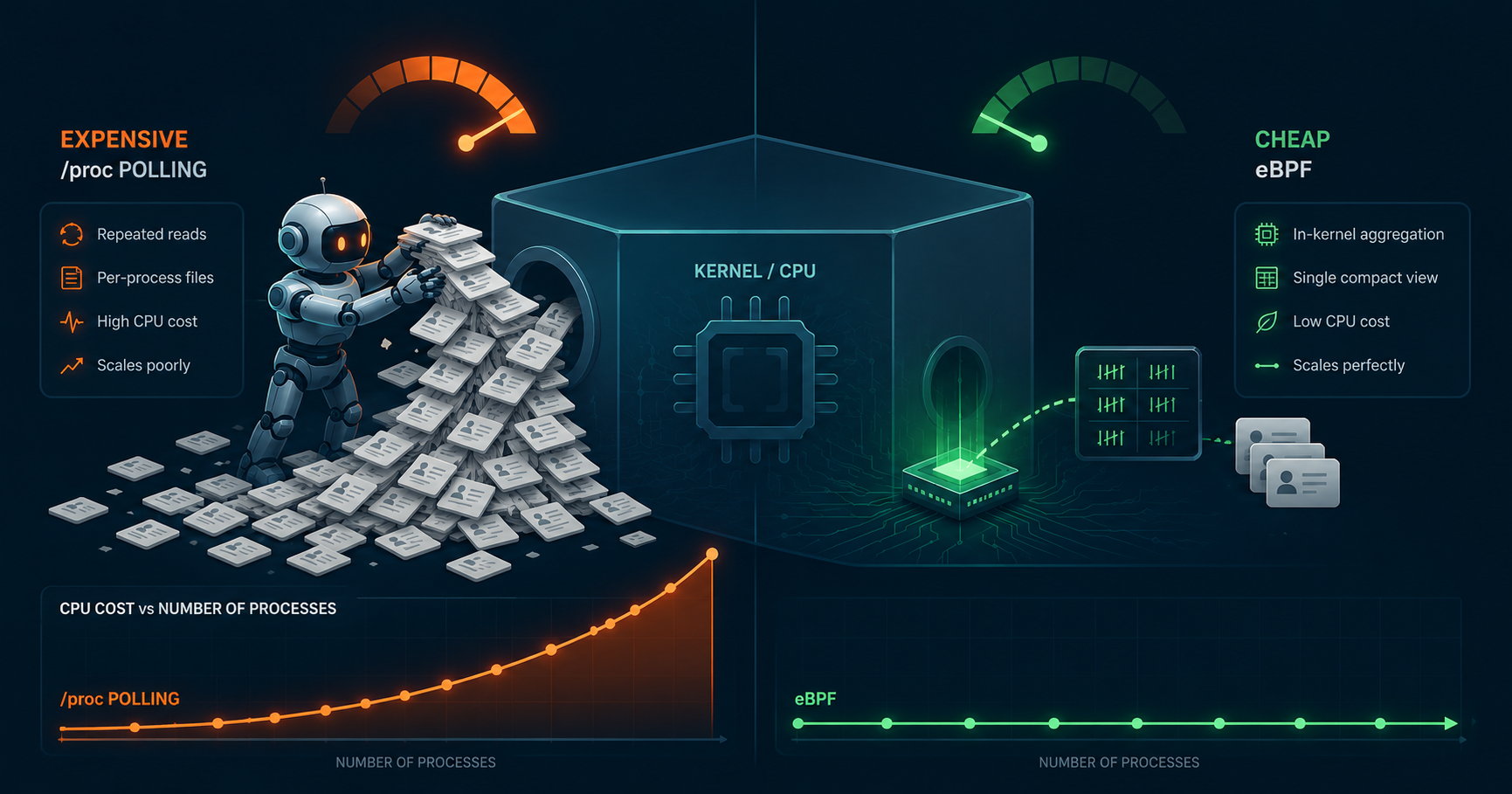
eBPF vs /proc 監控開銷——eBPF 較省,且規模越大差距越大
Lima VM 裡量了輪詢 /proc 與 eBPF 收主機 metrics 的 CPU 成本。eBPF 在每個場景都較省——沒有任何一次是 /proc 反而較快。差距在只收一兩個系統層級 gauge 時很小(落在雜訊內),在 per-process 指標時很大(~100 Process 約 4 倍、~600 Process 約 17 倍),且隨你追蹤的 Process 數量增加而擴大。
本系列把我在 iThome KubeSummit 2025 的演講,變成一篇篇你能在自己機器上實際跑起來的動手做指南。前兩篇談了「eBPF 是什麼」與「在 Mac 上建置開發環境」;這篇我們動手量一個常被忽略的東西——監控本身要花多少 CPU,並用一個你能自己重現的 benchmark,誠實比較 /proc 輪詢與 eBPF
TL;DR: eBPF 直接在 kernel 裡讀結構化資料,不必付
/proc每次 scrape 都要繳的「文字序列化+解析」稅。在我的 Lima VM 實測裡,eBPF 在每個場景都較省——沒有任何一次是/proc較快。 收一兩個系統層級 gauge(總 CPU%、記憶體)時差距很小,落在每輪雜訊內;收 per-process 指標時(輪詢得對每個 Process 各開一個檔案解析),eBPF 在 ~100 個 Process 時省約 4 倍、~600 個 Process 時約 17 倍,且隨你追蹤的 Process 數量越多、差距越大。省多少,取決於你收集的規模(Process 數、指標數量、頻率)
問題:監控的成本,以及為什麼 eBPF 讀得比較省
幾乎每台 production 主機都跑著監控 agent——node-exporter、cAdvisor 或自寫腳本——每隔幾秒醒來,讀一批 /proc 檔案、解析出數字、送出去。它在每台節點上全天候運轉,卻幾乎沒人測量過它的成本。
eBPF 讀同一份資料更省:它直接從 kernel 拿結構化數值,省掉 /proc 每次 scrape 都要做的文字序列化與解析,所以它的成本不會比 /proc 高。省多少,取決於你收集的規模:只收一兩個 gauge 時省得極少,收很多 Process 的 per-process 指標時省很多。
你會學到
- 為什麼讀同一份 kernel 資料,eBPF 不會比 /proc 貴、通常還更省
- 為什麼系統 gauge 差距很小、per-process 差距很大
- 怎麼公平地量——包含大多數 benchmark 會漏掉的 kernel 端成本
兩種模式,兩種大小的差距
系統 gauge——總 CPU%、記憶體、一個磁碟/網路 counter。/proc 用一兩個小檔案(/proc/stat、/proc/meminfo)就能給。eBPF 在 kernel 裡讀同樣的 counter、省掉文字解析,所以還是略省一點——但只有一兩個檔案,差距很小:在單機上落在每輪雜訊內
per-process 指標——每個容器/每個 PID 的 CPU。這正是 agent 為每個 workload 都會收的指標,也是輪詢增加成本的地方:它必須對主機上每個 Process、每次 scrape 都進行 open / read / 解析 /proc/<pid>/stat——是 O(Process 數量),連完全沒在做事的 Process 也要掃
per-process 的 eBPF 做法:在 kernel 累加、便宜地讀
與其每個 interval 重掃一次所有 Process,不如掛在 kernel 的 sched_switch 上,在切換當下就把每個 task 的 on-CPU 時間累加進一張 per-PID map。user space 接著每個 interval 只要把 map 撈出來(drain):
- 它只會看到真的有跑的 pid——睡著的 Process 完全不花成本(沒有檔案要開)
- reader 做的是 O(有在跑的 pid) 次 map 讀取,不是 O(所有 pid) 次檔案解析
- 唯一持續的成本是
sched_switchhook 本身,它跟著context-switch 速率走,而不是 Process 數量
這正是 eBPF 事件驅動模型真正發揮價值的地方:在 kernel 裡持續累加、便宜地讀——而不是像輪詢那樣每次都把全部重掃一遍
實驗
🔬 關於環境 我是在一台 Apple Silicon Mac(arm64)上的 Lima VM 裡跑的——不是裸機、也不是 production 節點。筆電上的 VM 是個較為複雜的環境,拿來量「一顆核不到 1%」的開銷時:hypervisor 排程、主機爭用、CPU 核心遷移都會放大變異,而且 arm64 跟典型 x86 production 節點不一樣。所以請把絕對數字當成方向與量級的參考,而不是 production 數據。我會把每輪之間的變異數列出來;相對結果與「怎麼隨規模放大」才是可信的部分
環境
- 主機:Apple Silicon Mac · Guest:Lima(Apple Virtualization
vz),Ubuntu 24.04,kernel 6.8(aarch64),2 vCPU / 4 GB uname -r:6.8.0-124-generic
測量內容 — 對所有 Process 收 per-process CPU(utime+stime),兩邊用同樣的間隔:
/procpoller:每個 interval 掃/proc,對每個/proc/<pid>/stat做open/read/解析- eBPF:
sched_switch把每個 task 的 on-CPU ns 累加進 hash map,reader 每個 interval drain 一次 - 我另外也跑了一個系統 gauge 版本(
/proc/statvs 用 BPF timer 讀 kernel counter)當對照
公平計算 eBPF 成本(多數 benchmark 漏掉的地方) — sched_switch 跑在排程器裡,算在「正在切換的那個 task」頭上,不是 reader。所以我算的是 reader cgroup 的 CPU(systemd CPUUsageNSec,ns 精度)+ BPF 程式自己的 kernel 時間。因為 sched_switch 是 tracepoint,它的 CPU 會被 bpf_stats(run_time_ns)算到——我透過 program fd 讀出來再加上去。只算 reader 會低估 eBPF。
確保公平 — 兩邊同一組指標、同樣間隔;跑 6–8 輪、每輪 20 秒,交錯/輪流先後,第一輪當暖機丟掉,以 mean ± stddev 呈現;在兩個 Process 數量下量(~100,以及用大量閒置 Process 撐到 ~600),看差距怎麼隨規模放大。
結果(% of 一顆核,Lima VM)
| 場景 | /proc (mean ± sd) | eBPF reader+kernel (mean ± sd) | Δ | /proc 曾較省? |
|---|---|---|---|---|
| 系統 gauge(輕量) | ~0.03% | ~0.02% | ~1.3×(eBPF 較低) | 否——差距落在雜訊內 |
| Per-process,~100 Process | 0.30% ± 0.055% | 0.076% ± 0.022% | 3.9× | 否 |
| Per-process,~600 Process | 1.18% ± 0.13% | 0.071% ± 0.004% | 16.6× | 否 |
讀這張表: eBPF 在每個場景都較省——沒有任何一次是 /proc 贏過 eBPF 收輕量的系統 gauge時差距很小,落在每輪雜訊內,單機上你不會有感。per-process 的差距大且可靠(超出雜訊、steal 0%),而且隨 Process 數量放大——我的實測是 ~100 Process 3.9×、~600 Process 16.6×:/proc 的成本跟著所有 Process 走,eBPF 幾乎持平(只跟著有在跑的 Process+context-switch 速率走)。就絕對值而言,這在單機上仍只是一顆核的一小部分——eBPF 真正有感的是在 Process 密度與機隊規模。
核心 code
eBPF collector 的核心:每次 context switch,就把切出去的 task 的 on-CPU 時間加進 per-PID map。這是「形狀」的示意,不是真正的 benchmark 程式碼——完整可跑的版本在 repo 裡。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Sketch — accumulate per-PID on-CPU time on each context switch.
SEC("tracepoint/sched/sched_switch")
int on_switch(struct trace_event_raw_sched_switch *ctx)
{
__u64 now = bpf_ktime_get_ns(), *last, *acc;
__u32 zero = 0, prev = (__u32)ctx->prev_pid;
last = bpf_map_lookup_elem(&last_ts, &zero); // CPU 上「被排進來」的時間戳
if (last && *last) {
__u64 dt = now - *last;
acc = bpf_map_lookup_elem(&cpu_ns, &prev);
if (acc) *acc += dt; else bpf_map_update_elem(&cpu_ns, &prev, &dt, BPF_ANY);
}
if (last) *last = now;
return 0;
}
// user space:每個 interval drain 一次 cpu_ns —— O(有在跑的 pid),不開任何 /proc 檔
👉 完整、可直接跑的 benchmark(兩種場景都有):hyperredstart/hello-ebpf → proc-vs-ebpf/
eBPF 的優勢什麼時候小、什麼時候大
兩種情況 eBPF 都較省,差別只在幅度:
優勢最小(不值得只為它特地換掉現有做法):
- 只收一兩個系統層級 gauge。
/proc/stat//proc/meminfo本來就便宜,eBPF 的優勢落在雜訊內 - Process 少/低密度。 在 Process 變多之前,per-process 差距只是一顆核的一小部分
幅度最大、最划算的情況:
- 高 pod/Process 密度。 Process 越多,輪詢每次 scrape 要掃的
/proc檔越多,而 eBPF 只為有跑的Process進行額外開銷——差距正好在會痛的地方放大 - 大規模收 per-process/per-container 指標。 這就是 node-exporter/cAdvisor 的成本,乘上整個機隊:在 ~600 Process/節點時,eBPF 每節點省 ~1.1% 顆核(1.18% → 0.07%);× 1,000 節點 ≈ 11 顆核
- 一個不能略過的但書: 如果你的 Process 很忙(context-switch 速率高),eBPF 的
sched_switch成本也會上升。差距最大的情況是 Process 多但 churn 中等——而這正是大多數容器機隊的樣子
測量收集規模,就知道能省多少
重點整理
- eBPF 直接讀 kernel 資料、省掉文字解析成本——它這套做法更省,而且在每個測試裡都贏(
/proc) - 系統 gauge:eBPF 只贏一點點(落在雜訊內)——不值得只為它特地換掉現有做法
- per-process 在密度下:eBPF 大勝——kernel 裡付 O(有在跑的 pid),輪詢付 O(所有 Process) 的檔案 I/O,且差距隨 Process 數量放大
延伸資源
- 完整 benchmark(兩種場景):hyperredstart/hello-ebpf → proc-vs-ebpf/
- 《BPF Performance Tools》— Brendan Gregg
- ebpf.io
你現在都怎麼量自己的監控開銷?我很好奇大家實際看到的數字——歡迎留言聊聊